Blog
April 14th, 2022
Creating a data lakehouse with DBT and Redshift

Written byJasmine Vickery • Senior Software Engineer
The first data lake we had, sucked.
We use DynamoDB heavily in our production stack. To slice and dice the data to create any kind of report, we need to get it into a relational database.
We had initially set up a system of Glue jobs. Each one connected to a DynamoDB table, ran a script to extract each of the fields on the JSON blob, then loaded the data into Amazon Redshift.
This did not prove to be a very robust solution.
As it turned out, the Glue Jobs were very expensive! This was because we were copying and replacing the whole DynamoDB table into Redshift every time they ran. The jobs cost us so much money that we had to turn them off in our development sandbox. And since we couldn't test them locally, we had to merge and then deploy our changes to our Staging environment. After that we would need to manually trigger them and wait till they finished. One minor bug took me three days to fix due to this slow development time.
In fact, that bug and the nightmare I faced fixing it was what kicked off the plan to get the entire platform improved.
The Glue Jobs were also very flakey, and it was common for them to fail and alert all the time. This was on top of them auto-retrying, and only alerting if there were two failures in a row.
Anyone using the data lake had to deal with data that was between one and twenty-four hours out-of-date.
We had three schedules for these jobs - a couple of high-priority tables that ran every hour, a three hour schedule, and a daily schedule. This was if none of the jobs had a failure and started auto-retrying.
These very long delays in the schedules were confusing. They sometimes led non-engineers to think our app was broken, leading to the creation of incidents.
Not only that, we started feeling the limits of our analytics tooling. While it did allow you to store the queries in git, this process wasn’t enforced, and many users weren't comfortable with it. We also couldn’t reuse SQL duplicated between reports.
We have some DynamoDB tables with a composite primary key. (Two strings concatenated with a `|` between them - it’s not a first-class feature of DynamoDB). When diagnosing issues, it was difficult to look up data because you needed to find both parts of the id. We didn't want the financial cost of secondary indices on those tables, so we had to use the primary key to look records up. And because many of these tables were on a daily schedule, the relational schema in the data lake was often of no help when we needed to look at them.
Goal
We needed a cheaper analytics data warehouse with much fresher data. And we wanted the process to be more robust than Glue was, removing the flakiness.
To reduce the costs of copying our entire database every single day, we wanted to only send new data into the data lake. We could then insert it into the existing tables.
We still wanted to source control the transformation on the raw JSON blob. But, we didn’t want this transformation to happen before the data reached Redshift, since it was brittle and difficult to test.
This would mean we’d need to put this transformation that extracted the columns from the JSON into the SQL itself. However, I was cautious about this.
In my opinion, one of the worst situations of tech debt you can get into is having a ton of critical SQL business logic crammed into one or two SQL files. And these files generate reports on a schedule with each new bucket of data, with no way to test them.
I had been burned by situations like that in the past and wanted to avoid those problems here.
What we did
We kept Redshift, but instead of using ETL (Extract, Transform, Load), we switched to ELT (Extract, Load, Transform).
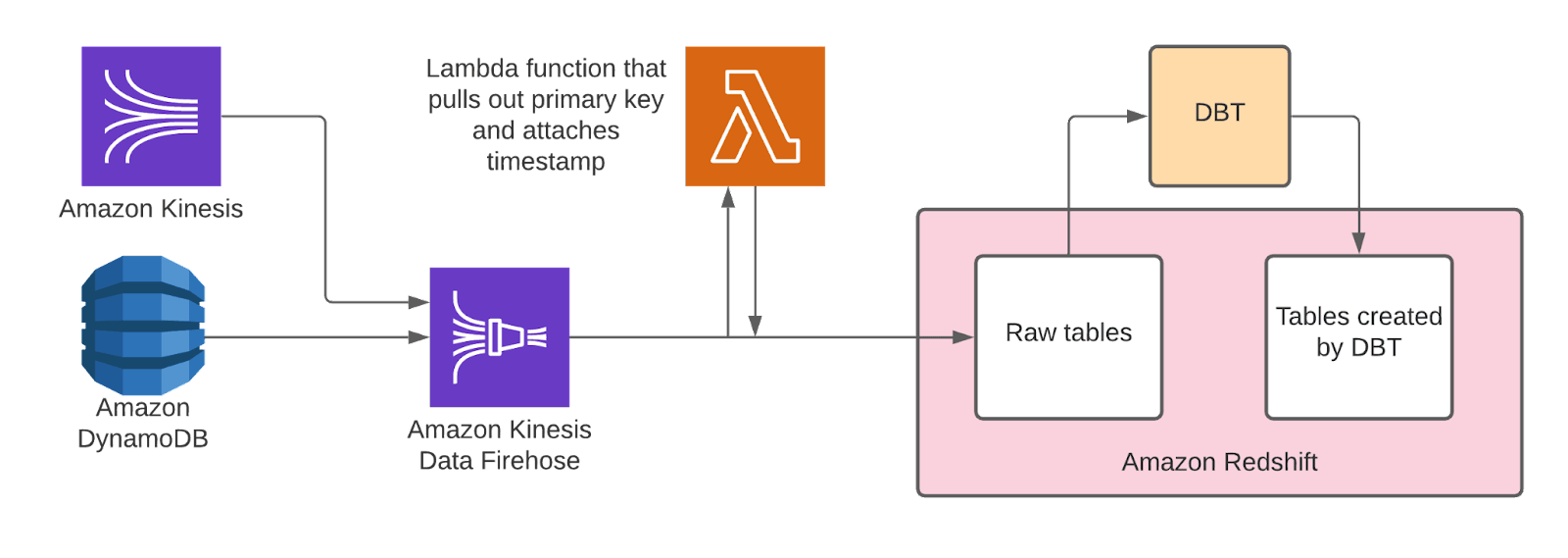
We accomplished this by creating Kinesis Firehoses to pipe the raw data straight from our DynamoDB and Kinesis streams into their own Redshift tables. We then create extra tables with the transformed data with a tool called DBT.
Attached to each of the Firehoses is a Lambda function which pulls out the primary keys from the data blobs and adds a timestamp for when they were processed.
Bronze/Silver/Gold
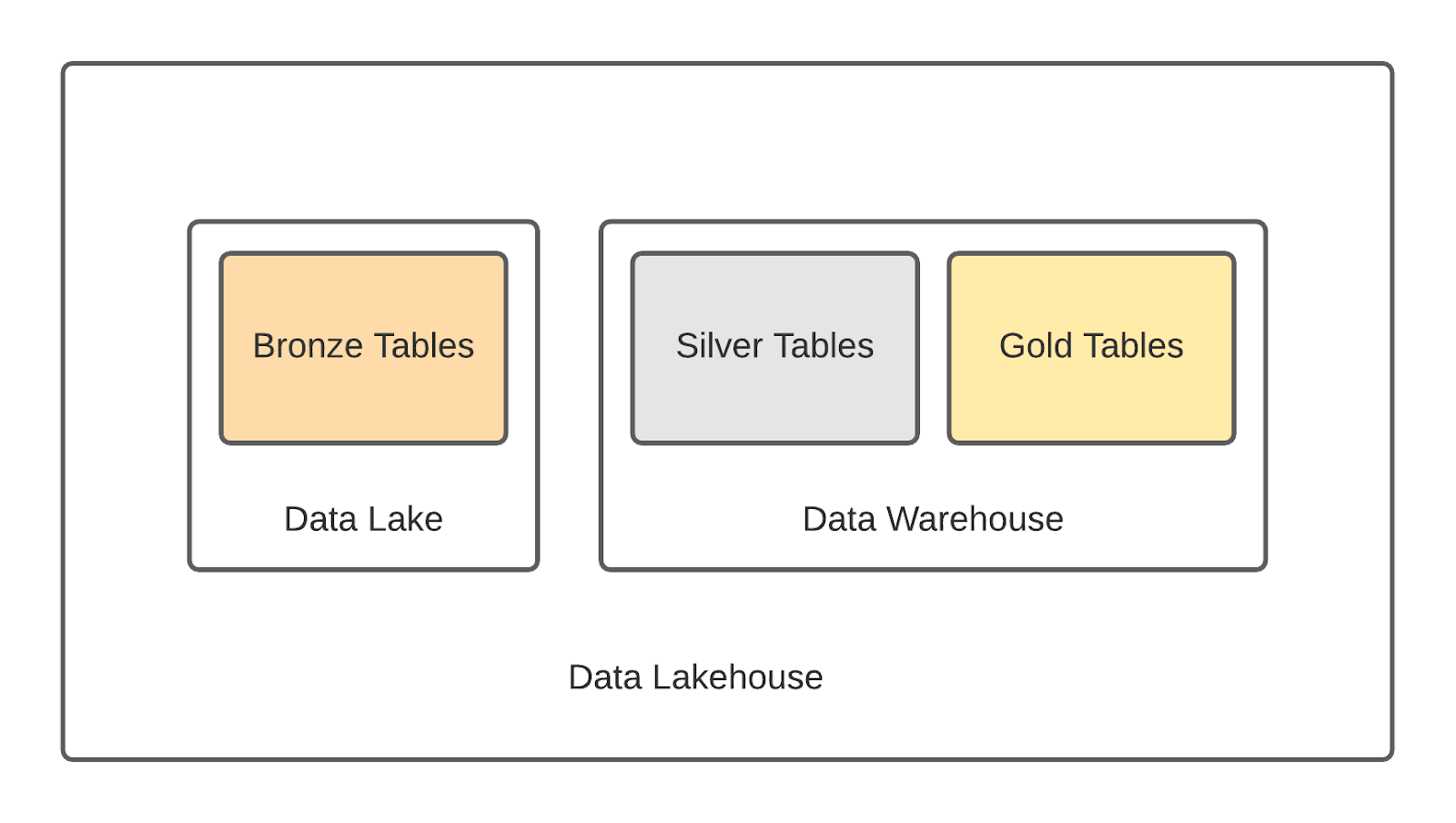
To help keep track of the kinds of transformations happening in Redshift, we created the concept of ‘bronze’, ‘silver’, and ‘gold’ tables. ‘Bronze’ tables contain raw data and initial transformations on it that aren’t cleaned up for use. These make up the ‘data lake’. Next, we have silver tables, where each of the columns from the data blob has been extracted into their own columns. Any dates given in milliseconds are formatted nicely, etc.
Finally, we have the gold tables. These use the silver tables to create business reports that need to be source-controlled and tested. The gold tables also contain a couple of product features that need to aggregate data on a relational schema. Together, silver and gold tables make up our Data Warehouse.
Given this, we decided to call the new version of our ‘data lake’ a ‘data lakehouse’.

Transforming the raw Redshift data
Now, we have all these raw JSON blobs sitting in our bronze tables. All the rows have a primary key, the data blob, and the timestamp for when we put them into Redshift.
We then convert them into a silver table with all the fields unnested into top-level columns. Any useful arrays are split into their own tables.
We could create views in Redshift on top of them with the transformations embedded in the SQL. However, we have some tables which are very large. If we used a view for them, we would need to do the transformation across the whole table every time we queried it. This would make views a lot slower and expensive here.
Stacking too many views on top of each other also stops the query optimiser from being able to work properly. This limits how much we can split the SQL up into modular chunks. We’d also need a way to test and assert on the results of each transformation step.
What we want to do next is to find a way to write a query which finds all the data in the bronze table that is more recent than the latest data in the silver table. We would then need to transform that data and insert it into the silver table. We’d also need to manage scheduling runs, and a way to test any changes.
DBT
This is where DBT comes in. DBT is a tool that allows us to create additional tables and models in Redshift (and other databases) by writing SELECT statements. The transformation logic goes in the SQL, and the results go into a new table (or view) that DBT calls a _model_.
These models can read data from our source tables (from our Dynamo and Kinesis streams) or from other DBT models. Since we are creating real database tables, we can stack our transformations as deep as we like, splitting our SQL files into logical chunks.
To keep our data fresh, we’ve scheduled DBT jobs to run our SQL queries and update the tables with new data every 15 minutes.
Incremental models
DBT includes features that help with building models that only accept data we tell it to filter for. In our case the new data that has arrived since it last ran.
Full refresh
Sometimes, even with all this tooling, we might make a mistake. Or change our minds on how something should be calculated. Fortunately, we’re not limited to only calculating the shape of new data for an incremental model. We can tell DBT to run a ‘full refresh’ on the model and recalculate all the data in the table.
Dev playground
So now we have a fantastic way to source-control our data transformations, automate the update schedule, and break our complex SQL into small, manageable chunks. But how can we verify that a change to the transformation won’t break anything?
In theory, if we wanted to update a model, we could manually create a test table in Redshift with data from our new transformation. But then we’d need to see if the data in our new transformation broke anything in any of the models that depended on it. We’d also need to drop the test table when we were done, and manually dropping test tables in a live database is risky. While we could mitigate this by developing in a sandbox, we wouldn’t know if our transformation worked till we deployed it.
Fortunately, there is another impressive feature that DBT comes with out of the box. It has the ability to automatically create a separate developer schema per user in your database. DBT duplicates all the models and populates them with all or some of the data from the live schema to develop against. This means we can easily preview how a simple change will affect the live data and transformations end to end.
Automated tests against real data
DBT gives us a fantastic way of manually testing our changes. But is there any way to automate testing our data health and transformations?
Fortunately, DBT provides a wide range of options for testing.
First up, there are ‘singular tests’, where you write a SELECT statement over the tables or columns you need. If the query returns any rows, the test fails. These tests aren’t reusable for other tables or columns.
Then there are ‘generic tests’, which take a table and optionally a column to perform a more generic assertion. Things like ‘every value in this column should be present’ or ‘every value in this column should be unique'. There are several of these that come with DBT or popular libraries, so you often don’t have to write your own.
Unit tests
It’s exciting to be able to preview SQL against real production data and run automated tests against it. But often in programming we want to write Unit Tests. We wanted to mock the input table(s) for a model with a row or two of static input data. Then we could compare the result of the transformation against an expected result.
DBT doesn’t have good support for this yet, but it is possible and we decided to go with the dbt-datamocktool library.
While I initially set up our test input using CSV seeds, I found they weren’t able to handle arrays or inferring the correct types of timestamps properly. We started creating our mocks [using SQL](https://github.com/mjirv/dbt-datamocktool#using-other-materializations), and only compare the columns we’re interested in.
CI
When we open a pull request with our changes, DBT also creates a schema corresponding to our PR. It runs any commands and tests we've specified and confirms they pass. It also automatically performs the cleanup afterward.

Datafold
In addition to the DBT checks and tests, we set up another tool called Datafold. This tool analyses the difference between the data in the production tables, and the data in the temporary tables for the Pull Request. Datafold annotates the PR with a report summarising its findings. If it detects any major differences, it will soft-fail the PR. The insights it provides include new or removed columns and tables, drastic differences in row count, and rows without primary keys.
Monitoring and alerting
Given we use this system in parts of our live product features, we need to have a robust monitoring system in case any tables go down. We queried the [DBT Metadata API](https://docs.getdbt.com/docs/dbt-cloud/dbt-cloud-api/metadata/metadata-overview) with a Lambda that pulled out the metrics we need in and sent them to Datadog. From there we made a dashboard and set up a system of alerts to warn us if any transformations start failing or running behind.
Documentation
We can also add a description on each table and column in our config. DBT can gather these together and embed them into an auto-generated documentation site. DBT can also auto-generate a dependency diagram that details which models depend on which.
Results
Once we got every table migrated, the results were phenomenal.
We made a cost saving of over 20% of our monthly AWS budget. We had also just performed some other AWS cost reduction work that saved the same amount. This led to our AWS account manager contacting us concerned we were switching to Azure!
Everyone at Vital has really appreciated the freshness and flexibility of the new Lakehouse. To the point where we are thinking about some new features that will require an even higher level of freshness. (We’re looking into accomplishing this with a separate high-frequency DBT job).
We’ve even been able to embed hospital-specific reports in our Vital Inpatient app, so our clients can benefit from these analytics, too.
Challenges
Given the way we are continually adding data to our tables, we need to schedule Redshift to regularly perform a VACUUM operation. Sometimes, when it’s time to vacuum one of our larger tables, the runs adding new data to the table can get stuck behind the vacuum job and cause data-freshness delays of up to two hours.
If you’re looking for an interesting and meaningful technology challenge in an inclusive and flexible work environment, or you’re just curious to find out more about what it’s like to work at Vital, you can find out more on our careers page.